您现在的位置是:首页 > cms教程 > WordPress教程WordPress教程
wordpress博客怎么写robots.txt
![]() 王封安2025-02-19WordPress教程已有人查阅
王封安2025-02-19WordPress教程已有人查阅
导读Robots.txt是放在博客根目录给搜索引擎看的一个文件,告诉搜索引擎什么链接能收录什么链接不能收录以及什么搜索引擎能够收录,在SEO中有着举足轻重的作用。
Robots.txt是放在博客根目录给搜索引擎看的一个文件,告诉搜索引擎什么链接能收录什么链接不能收录以及什么搜索引擎能够收录,在SEO中有着举足轻重的作用。
WordPress本身就有很多地方是非添加robots.txt不可的,比如:
用了伪静态链接之后动态链接依然能访问博客。
用Wordpress架设的博客有很多不同链接但相同内容的页面。Robots.txt的误区
不添加Robots.txt
Robots.txt作为搜索引擎机器人来到网站查看的第一个文件是很有必要精心设置的,搜索引擎机器人访问网站时,首先会查看站点根目录有没有Robots.txt文件,如果有这个文件就根据文件的内容确定收录范围,如果没有就默认访问以及收录所有页面。这是不是意味着,要想让搜索引擎收录全部链接就可以不设置这个文件了?其实不是的,搜索引擎机器人查看没有Robots.txt文件的时候就产生一个404错误日志在服务器上,增加服务器的负担。
Robots.txt文件Allow所有页面
这是平时比较容易犯到的错误,以为要让搜索引擎更多地收录网站就设置Robots.txt为:
User-agent: baiduspider 表示对百度机器人起作用。
User-agent: * 表示对所有搜索引擎机器人起作用。
Robots.txt文档中至少要有一条User-agent:记录而User-agent: * 记录只允许有一条。
Disallow: /giisi 表示不允许搜索引擎访问或者收录/giisi.html、/giisi/index.html、/giisi.php等包含/giisi的链接,而Disallow: /giisi/则允许访问/giisi.html、/giisi.php等,但是禁止访问/giisi/index.html。
Disallow: / 表示禁止搜索引擎机器人访问收录所有页面。订酒店返现金
Disallow: 表示允许搜索引擎访问收录所有页面。
Allow: /giisi 表示允许搜索引擎访问或者收录/giisi.html、/giisi/index.html、/giisi.php等包含/giisi的链接,而Allow:/giisi/则表示允许搜索引擎机器人访问/giisi/index.html等链接,但是对/giisi.html、/giisi.php未置可否。
“*”和“$”通配符
Disallow: */comments 表示不允许访问和收录所有wordpress评论留言页面。比如:http://域名/born/tianxie zhuanchushenqingbiao.html#comment-3715 是禁止收录的。
Disallow: /category/*/page/ 表示禁止访问和收录分类的相关分页。比如集思博客中网页设计分类有很多页面:
http://域名/category/design/page/2
记录中用“*”通配符表示了分类的别称“design”。
Disallow: .jpg$ 和Disallow: .php$ 分别表示禁止访问收录“,jpg”和“.php”后缀的文件集思博客的Robots.txt
User-agent: *
Disallow: /*?* (屏蔽搜索引擎机器人收录动态网页,因为/?q=id也是能访问文章的哦!)
Disallow: /index.php (因为我的博客在windows主机呆过,发现域名/index.php/postname.html也能访问现在的日志)
Disallow: /wp-admin (屏蔽搜索引擎机器人收录管理界面)
Disallow: /wp-content/plugins (屏蔽搜索引擎机器人收录插件文件)
Disallow: /wp-content/themes (屏蔽搜索引擎机器人收录模板文件)
Disallow: /wp-includes (屏蔽搜索引擎机器人收录JS文件)
Disallow: /trackback (屏蔽搜索引擎机器人收录trackback等垃圾信息,关闭trackback的可以忽略)
Disallow: /feed (Feed中都是与日志相同的信息当然要屏蔽)
Disallow: /comments(下面三个上面有介绍了)
Disallow: /category/*/page/
Disallow: /tag/*/page/
Sitemap: http://域名/sitemap.xml (这个用来告诉搜索引擎sitemap的路径,我用了两个)
Sitemap: http://域名/sitemap_baidu.xml
Robots.txt是放在博客根目录给搜索引擎看的一个文件,告诉搜索引擎什么链接能收录什么链接不能收录以及什么搜索引擎能够收录,在SEO中有着举足轻重的作用。
WordPress本身就有很多地方是非添加robots.txt不可的,比如:
用了伪静态链接之后动态链接依然能访问博客。
用Wordpress架设的博客有很多不同链接但相同内容的页面。Robots.txt的误区
不添加Robots.txt
Robots.txt作为搜索引擎机器人来到网站查看的第一个文件是很有必要精心设置的,搜索引擎机器人访问网站时,首先会查看站点根目录有没有Robots.txt文件,如果有这个文件就根据文件的内容确定收录范围,如果没有就默认访问以及收录所有页面。这是不是意味着,要想让搜索引擎收录全部链接就可以不设置这个文件了?其实不是的,搜索引擎机器人查看没有Robots.txt文件的时候就产生一个404错误日志在服务器上,增加服务器的负担。
Robots.txt文件Allow所有页面
这是平时比较容易犯到的错误,以为要让搜索引擎更多地收录网站就设置Robots.txt为:
User-agent: *
Disallow:
或者:
User-agent: *
Allow: /
这样搜索引擎不单单收录了你文章页面,还收录了管理界面,模板链接,CSS、JS链接,虽然说WordPress的管理界面谁都可以猜得到,不怕泄漏出去,但是这样一来就浪费服务器的资源,而且搜索引擎收录了这些链接是不会增加网站收录数的。Robots.txt的写法Robots.txt文档以User-agent: 开头,标识语句对应的搜索引擎机器人,后面跟上Disallow: 和Allow:表示起作用的链接。
User-agent: baiduspider 表示对百度机器人起作用。
User-agent: * 表示对所有搜索引擎机器人起作用。
Robots.txt文档中至少要有一条User-agent:记录而User-agent: * 记录只允许有一条。
Disallow: /giisi 表示不允许搜索引擎访问或者收录/giisi.html、/giisi/index.html、/giisi.php等包含/giisi的链接,而Disallow: /giisi/则允许访问/giisi.html、/giisi.php等,但是禁止访问/giisi/index.html。
Disallow: / 表示禁止搜索引擎机器人访问收录所有页面。
Disallow: 表示允许搜索引擎访问收录所有页面。
Allow: /giisi 表示允许搜索引擎访问或者收录/giisi.html、/giisi/index.html、/giisi.php等包含/giisi的链接,而Allow:/giisi/则表示允许搜索引擎机器人访问/giisi/index.html等链接,但是对/giisi.html、/giisi.php未置可否。
“*”和“$”通配符
Disallow: */comments 表示不允许访问和收录所有wordpress评论留言页面。比如:http://域名/born/tianxie zhuanchushenqingbiao.html#comment-3715 是禁止收录的。
Disallow: /category/*/page/ 表示禁止访问和收录分类的相关分页。比如集思博客中网页设计分类有很多页面:
http://域名/category/design/page/2
记录中用“*”通配符表示了分类的别称“design”。
Disallow: .jpg$ 和Disallow: .php$ 分别表示禁止访问收录“,jpg”和“.php”后缀的文件集思博客的Robots.txt
User-agent: *
Disallow: /*?* (屏蔽搜索引擎机器人收录动态网页,因为/?q=id也是能访问文章的哦!)
Disallow: /index.php (因为我的博客在windows主机呆过,发现域名/index.php/postname.html也能访问现在的日志)
Disallow: /wp-admin (屏蔽搜索引擎机器人收录管理界面)
Disallow: /wp-content/plugins (屏蔽搜索引擎机器人收录插件文件)
Disallow: /wp-content/themes (屏蔽搜索引擎机器人收录模板文件)
Disallow: /wp-includes (屏蔽搜索引擎机器人收录JS文件)
Disallow: /trackback (屏蔽搜索引擎机器人收录trackback等垃圾信息,关闭trackback的可以忽略)
Disallow: /feed (Feed中都是与日志相同的信息当然要屏蔽)
Disallow: /comments(下面三个上面有介绍了)
Disallow: /category/*/page/
Disallow: /tag/*/page/
Sitemap: http://域名/sitemap.xml (这个用来告诉搜索引擎sitemap的路径,我用了两个)
Sitemap: http://域名/sitemap_baidu.xml


WordPress本身就有很多地方是非添加robots.txt不可的,比如:
用了伪静态链接之后动态链接依然能访问博客。
用Wordpress架设的博客有很多不同链接但相同内容的页面。Robots.txt的误区
不添加Robots.txt
Robots.txt作为搜索引擎机器人来到网站查看的第一个文件是很有必要精心设置的,搜索引擎机器人访问网站时,首先会查看站点根目录有没有Robots.txt文件,如果有这个文件就根据文件的内容确定收录范围,如果没有就默认访问以及收录所有页面。这是不是意味着,要想让搜索引擎收录全部链接就可以不设置这个文件了?其实不是的,搜索引擎机器人查看没有Robots.txt文件的时候就产生一个404错误日志在服务器上,增加服务器的负担。
Robots.txt文件Allow所有页面
这是平时比较容易犯到的错误,以为要让搜索引擎更多地收录网站就设置Robots.txt为:
User-agent: *
Disallow:
或者:
User-agent: *
Allow: /
这样搜索引擎不单单收录了你文章页面,还收录了管理界面,模板链接,CSS、JS链接,虽然说WordPress的管理界面谁都可以猜得到,不怕泄漏出去,但是这样一来就浪费服务器的资源,而且搜索引擎收录了这些链接是不会增加网站收录数的。Robots.txt的写法Robots.txt文档以User-agent: 开头,标识语句对应的搜索引擎机器人,后面跟上Disallow: 和Allow:表示起作用的链接。User-agent: baiduspider 表示对百度机器人起作用。
User-agent: * 表示对所有搜索引擎机器人起作用。
Robots.txt文档中至少要有一条User-agent:记录而User-agent: * 记录只允许有一条。
Disallow: /giisi 表示不允许搜索引擎访问或者收录/giisi.html、/giisi/index.html、/giisi.php等包含/giisi的链接,而Disallow: /giisi/则允许访问/giisi.html、/giisi.php等,但是禁止访问/giisi/index.html。
Disallow: / 表示禁止搜索引擎机器人访问收录所有页面。订酒店返现金
Disallow: 表示允许搜索引擎访问收录所有页面。
Allow: /giisi 表示允许搜索引擎访问或者收录/giisi.html、/giisi/index.html、/giisi.php等包含/giisi的链接,而Allow:/giisi/则表示允许搜索引擎机器人访问/giisi/index.html等链接,但是对/giisi.html、/giisi.php未置可否。
“*”和“$”通配符
Disallow: */comments 表示不允许访问和收录所有wordpress评论留言页面。比如:http://域名/born/tianxie zhuanchushenqingbiao.html#comment-3715 是禁止收录的。
Disallow: /category/*/page/ 表示禁止访问和收录分类的相关分页。比如集思博客中网页设计分类有很多页面:
http://域名/category/design/page/2
记录中用“*”通配符表示了分类的别称“design”。
Disallow: .jpg$ 和Disallow: .php$ 分别表示禁止访问收录“,jpg”和“.php”后缀的文件集思博客的Robots.txt
User-agent: *
Disallow: /*?* (屏蔽搜索引擎机器人收录动态网页,因为/?q=id也是能访问文章的哦!)
Disallow: /index.php (因为我的博客在windows主机呆过,发现域名/index.php/postname.html也能访问现在的日志)
Disallow: /wp-admin (屏蔽搜索引擎机器人收录管理界面)
Disallow: /wp-content/plugins (屏蔽搜索引擎机器人收录插件文件)
Disallow: /wp-content/themes (屏蔽搜索引擎机器人收录模板文件)
Disallow: /wp-includes (屏蔽搜索引擎机器人收录JS文件)
Disallow: /trackback (屏蔽搜索引擎机器人收录trackback等垃圾信息,关闭trackback的可以忽略)
Disallow: /feed (Feed中都是与日志相同的信息当然要屏蔽)
Disallow: /comments(下面三个上面有介绍了)
Disallow: /category/*/page/
Disallow: /tag/*/page/
Sitemap: http://域名/sitemap.xml (这个用来告诉搜索引擎sitemap的路径,我用了两个)
Sitemap: http://域名/sitemap_baidu.xml
Robots.txt是放在博客根目录给搜索引擎看的一个文件,告诉搜索引擎什么链接能收录什么链接不能收录以及什么搜索引擎能够收录,在SEO中有着举足轻重的作用。
WordPress本身就有很多地方是非添加robots.txt不可的,比如:
用了伪静态链接之后动态链接依然能访问博客。
用Wordpress架设的博客有很多不同链接但相同内容的页面。Robots.txt的误区
不添加Robots.txt
Robots.txt作为搜索引擎机器人来到网站查看的第一个文件是很有必要精心设置的,搜索引擎机器人访问网站时,首先会查看站点根目录有没有Robots.txt文件,如果有这个文件就根据文件的内容确定收录范围,如果没有就默认访问以及收录所有页面。这是不是意味着,要想让搜索引擎收录全部链接就可以不设置这个文件了?其实不是的,搜索引擎机器人查看没有Robots.txt文件的时候就产生一个404错误日志在服务器上,增加服务器的负担。
Robots.txt文件Allow所有页面
这是平时比较容易犯到的错误,以为要让搜索引擎更多地收录网站就设置Robots.txt为:
User-agent: *
Disallow:
或者:
User-agent: *
Allow: /
这样搜索引擎不单单收录了你文章页面,还收录了管理界面,模板链接,CSS、JS链接,虽然说WordPress的管理界面谁都可以猜得到,不怕泄漏出去,但是这样一来就浪费服务器的资源,而且搜索引擎收录了这些链接是不会增加网站收录数的。Robots.txt的写法Robots.txt文档以User-agent: 开头,标识语句对应的搜索引擎机器人,后面跟上Disallow: 和Allow:表示起作用的链接。
User-agent: baiduspider 表示对百度机器人起作用。
User-agent: * 表示对所有搜索引擎机器人起作用。
Robots.txt文档中至少要有一条User-agent:记录而User-agent: * 记录只允许有一条。
Disallow: /giisi 表示不允许搜索引擎访问或者收录/giisi.html、/giisi/index.html、/giisi.php等包含/giisi的链接,而Disallow: /giisi/则允许访问/giisi.html、/giisi.php等,但是禁止访问/giisi/index.html。
Disallow: / 表示禁止搜索引擎机器人访问收录所有页面。
Disallow: 表示允许搜索引擎访问收录所有页面。
Allow: /giisi 表示允许搜索引擎访问或者收录/giisi.html、/giisi/index.html、/giisi.php等包含/giisi的链接,而Allow:/giisi/则表示允许搜索引擎机器人访问/giisi/index.html等链接,但是对/giisi.html、/giisi.php未置可否。
“*”和“$”通配符
Disallow: */comments 表示不允许访问和收录所有wordpress评论留言页面。比如:http://域名/born/tianxie zhuanchushenqingbiao.html#comment-3715 是禁止收录的。
Disallow: /category/*/page/ 表示禁止访问和收录分类的相关分页。比如集思博客中网页设计分类有很多页面:
http://域名/category/design/page/2
记录中用“*”通配符表示了分类的别称“design”。
Disallow: .jpg$ 和Disallow: .php$ 分别表示禁止访问收录“,jpg”和“.php”后缀的文件集思博客的Robots.txt
User-agent: *
Disallow: /*?* (屏蔽搜索引擎机器人收录动态网页,因为/?q=id也是能访问文章的哦!)
Disallow: /index.php (因为我的博客在windows主机呆过,发现域名/index.php/postname.html也能访问现在的日志)
Disallow: /wp-admin (屏蔽搜索引擎机器人收录管理界面)
Disallow: /wp-content/plugins (屏蔽搜索引擎机器人收录插件文件)
Disallow: /wp-content/themes (屏蔽搜索引擎机器人收录模板文件)
Disallow: /wp-includes (屏蔽搜索引擎机器人收录JS文件)
Disallow: /trackback (屏蔽搜索引擎机器人收录trackback等垃圾信息,关闭trackback的可以忽略)
Disallow: /feed (Feed中都是与日志相同的信息当然要屏蔽)
Disallow: /comments(下面三个上面有介绍了)
Disallow: /category/*/page/
Disallow: /tag/*/page/
Sitemap: http://域名/sitemap.xml (这个用来告诉搜索引擎sitemap的路径,我用了两个)
Sitemap: http://域名/sitemap_baidu.xml
感谢您的认可和支持
微信
支付宝
本文标签:
很赞哦! ()
图文教程

wordpress适合做什么样子的网站
很多人知道wordpress这个程序,这款风靡全球的程序实在是太强大,以至于已经从一个博客程序平台,变成了一款几乎无所不能的网站程序。
Wordpress根目录位置和FTP连接方法
1、获取FTP的账号和密码:查看FTP信息和进入空间管理面板(DA)2、获取服务器地址(IP地址):主机庙空间怎么查看空间IP地址
WordPress主题加载速度慢的优化方法
在header后调用PHP flush函数,可以加速WordPress博客。在header.php文件的结束标签前,加上以下的代码行: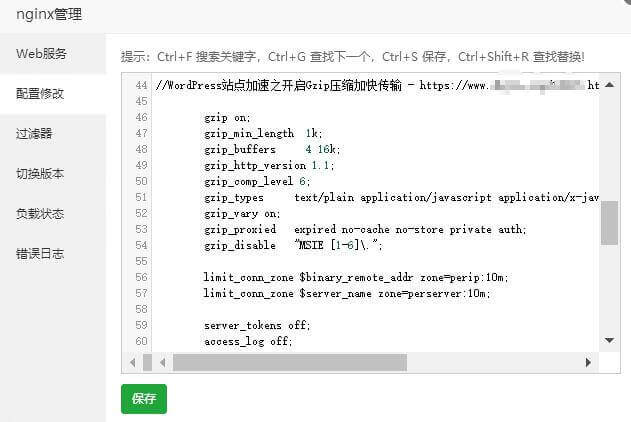
WordPress站点加速开启Gzip压缩的方法
最近没有使用Gzip压缩,因为它学会了打开这种压缩。 我对服务器上的设置,WordPress站点上的设置或插件上的设置感到困惑;经过几天的研究
相关源码
-
 (PC+WAP)历史复古古典古籍文章资讯类pbootcms模板下载本模板基于PbootCMS系统开发,为古籍研究、历史文献类网站设计,特别适合展示古典书籍、历史档案等文化内容。采用复古风格设计,同时具备现代化响应式布局,确保在PC和移动设备上都能呈现优雅的阅读体验。查看源码
(PC+WAP)历史复古古典古籍文章资讯类pbootcms模板下载本模板基于PbootCMS系统开发,为古籍研究、历史文献类网站设计,特别适合展示古典书籍、历史档案等文化内容。采用复古风格设计,同时具备现代化响应式布局,确保在PC和移动设备上都能呈现优雅的阅读体验。查看源码 -
 (自适应)简繁双语机械矿山矿石五金设备pbootcms源码下载本模板基于PbootCMS开发,主要面向机械五金、矿山矿石设备等行业,支持简体中文和繁体中文双语切换。采用响应式布局技术,确保在各种设备上都能获得良好的浏览体验。模板设计注重展示工业设备的专业性和技术特点,帮助企业建立可靠的线上展示平台。查看源码
(自适应)简繁双语机械矿山矿石五金设备pbootcms源码下载本模板基于PbootCMS开发,主要面向机械五金、矿山矿石设备等行业,支持简体中文和繁体中文双语切换。采用响应式布局技术,确保在各种设备上都能获得良好的浏览体验。模板设计注重展示工业设备的专业性和技术特点,帮助企业建立可靠的线上展示平台。查看源码 -
 (PC+WAP)高端餐饮美食小吃加盟网站模板下载pbootcms本模板基于PbootCMS内核开发,为餐饮美食品牌加盟、小吃连锁企业量身打造。通过精致的美食视觉呈现与加盟业务流程展示,帮助餐饮企业建立专业线上门户,实现品牌形象与加盟业务的双重展示。查看源码
(PC+WAP)高端餐饮美食小吃加盟网站模板下载pbootcms本模板基于PbootCMS内核开发,为餐饮美食品牌加盟、小吃连锁企业量身打造。通过精致的美食视觉呈现与加盟业务流程展示,帮助餐饮企业建立专业线上门户,实现品牌形象与加盟业务的双重展示。查看源码 -
 (PC+WAP)中英双语户外用品帐篷装备pbootcms网站模板下载这款基于PbootCMS开发的中英文双语模板专为户外装备行业设计,适配PC和移动设备。模板采用现代化设计风格,突出户外产品的功能性和实用性,帮助企业建立专业的国际化展示平台。查看源码
(PC+WAP)中英双语户外用品帐篷装备pbootcms网站模板下载这款基于PbootCMS开发的中英文双语模板专为户外装备行业设计,适配PC和移动设备。模板采用现代化设计风格,突出户外产品的功能性和实用性,帮助企业建立专业的国际化展示平台。查看源码 -
 pbootcms模板(PC+WAP)APP应用软件下载类官网源码为APP应用软件官网打造的响应式解决方案,PC端与移动端(WAP)数据实时同步,一次更新全网生效,满足多终端用户无缝体验需求。查看源码
pbootcms模板(PC+WAP)APP应用软件下载类官网源码为APP应用软件官网打造的响应式解决方案,PC端与移动端(WAP)数据实时同步,一次更新全网生效,满足多终端用户无缝体验需求。查看源码 -
 (自适应)pbootcms家政服务保洁保姆打扫卫生网站模板下载本模板基于PbootCMS内核开发,为家政服务企业量身定制。设计风格温馨亲切,突出家政行业的专业与贴心服务特性,多方位展示企业服务项目与优势。查看源码
(自适应)pbootcms家政服务保洁保姆打扫卫生网站模板下载本模板基于PbootCMS内核开发,为家政服务企业量身定制。设计风格温馨亲切,突出家政行业的专业与贴心服务特性,多方位展示企业服务项目与优势。查看源码
| 分享笔记 (共有 篇笔记) |






